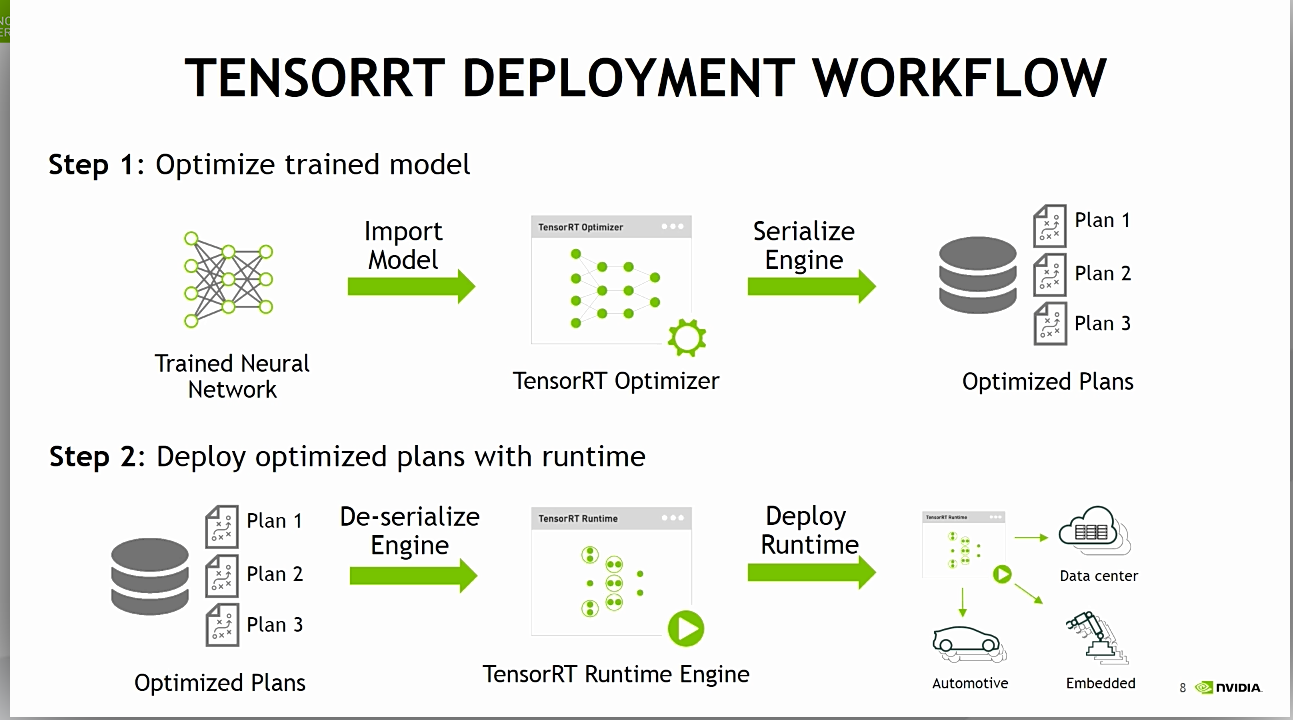
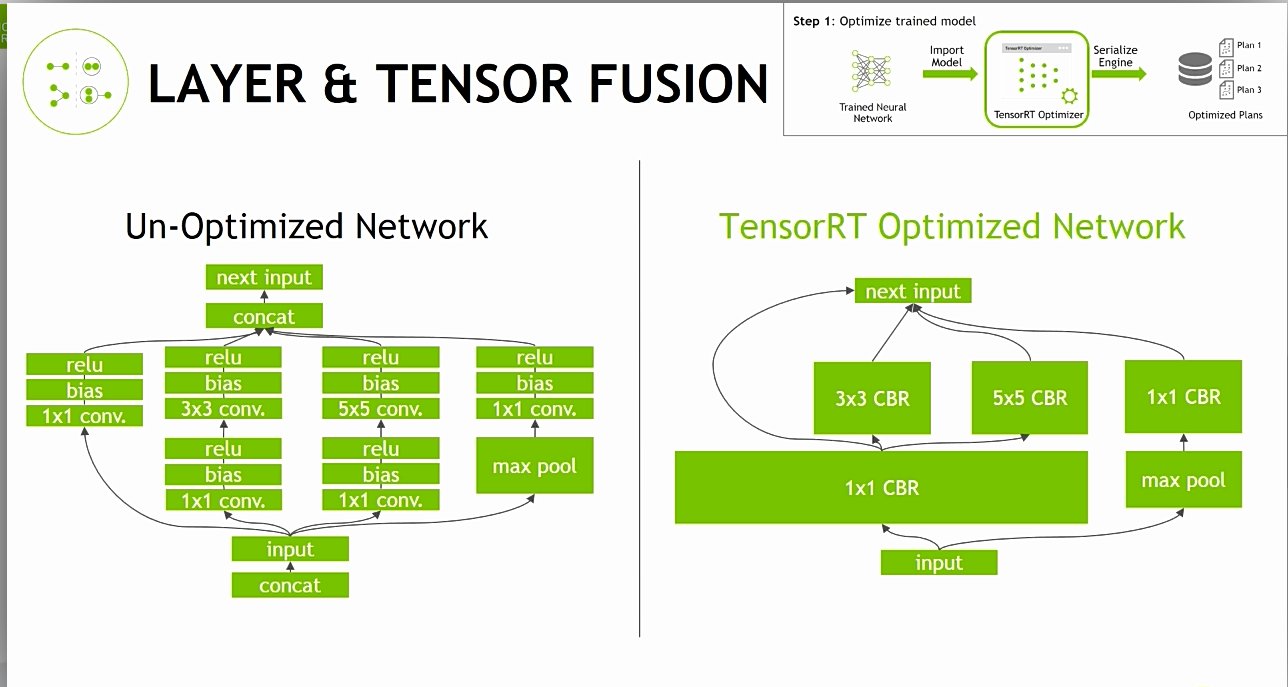
우선 TensorRT Python UFF Custom Layer Source를 이해하기전에 아래의 소스들을 기본적으로 이해를 하고 오는 것이 좋을 것 같다
- TensorRT Python Code 분석
https://ahyuo79.blogspot.com/2019/09/tensorrt-5-python-tensorflow-mnist.html
TensorRT 5 기본구조
https://ahyuo79.blogspot.com/2019/08/tensorrt-5-python.html
아래사항은 Tensorflow와 TensorRT 설치가이드이며 관련사항이므로 참고하자
- Tensorflow 와 TensorRT Package
https://docs.nvidia.com/deeplearning/sdk/tensorrt-install-guide/index.html#installing
1.1 TensorRT 소스구조 파악 과 실행
현재 모든 Manual이 X86기반으로 되어 있으므로, ARM Version이 맞게 이를 변경하고 관련된 Package를 설치하여 아래의 소스를 실행해보자
- UFF_Custom_PlugIn의 README 정보
https://docs.nvidia.com/deeplearning/sdk/tensorrt-sample-support-guide/index.html#uff_custom_plugin
- UFF Custom PlugIn 소스구조 및 필요사항 확인
$ cd /usr/src/tensorrt/samples/python/uff_custom_plugin
$ tree -t
.
├── CMakeLists.txt // cmake 필요
├── __init__.py
├── lenet5.py
├── README.md // 반드시 참조
├── requirements.txt
├── sample.py
└── plugin
├── clipKernel.cu // CUDA Complier 필요
├── clipKernel.h
├── customClipPlugin.cpp // GCC->G++ Compiler 필요
└── customClipPlugin.h
$ cat requirements.txt
Pillow
pycuda
numpy
tensorflow
- C++ PlugiN 빌드를 위해 cmake 설정 변경
$ vi CMakeLists.txt
# We need cmake >= 3.8, since 3.8 introduced CUDA as a first class language
cmake_minimum_required(VERSION 3.8 FATAL_ERROR)
project(ClipPlugin LANGUAGES CXX CUDA)
# Enable all compile warnings
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -Wno-long-long -pedantic -Werror")
# Sets variable to a value if variable is unset.
macro(set_ifndef var val)
if (NOT ${var})
set(${var} ${val})
endif()
message(STATUS "Configurable variable ${var} set to ${${var}}")
endmacro()
# -------- CONFIGURATION --------
##set_ifndef(TRT_LIB /usr/lib/x86_64-linux-gnu)
##set_ifndef(TRT_INCLUDE /usr/include/x86_64-linux-gnu)
set_ifndef(TRT_LIB /usr/lib/aarch64-linux-gnu/)
set_ifndef(TRT_INCLUDE /usr/include/aarch64-linux-gnu/ )
# Find dependencies:
message("\nThe following variables are derived from the values of the previous variables unless provided explicitly:\n")
# TensorRT's nvinfer lib
find_library(_NVINFER_LIB nvinfer HINTS ${TRT_LIB} PATH_SUFFIXES lib lib64)
set_ifndef(NVINFER_LIB ${_NVINFER_LIB})
# -------- BUILDING --------
# Add include directories
include_directories(${CUDA_INC_DIR} ${TRT_INCLUDE} ${CMAKE_SOURCE_DIR}/plugin/)
# Define clip plugin library target
add_library(clipplugin MODULE
${CMAKE_SOURCE_DIR}/plugin/clipKernel.cu
${CMAKE_SOURCE_DIR}/plugin/customClipPlugin.cpp
${CMAKE_SOURCE_DIR}/plugin/clipKernel.h
${CMAKE_SOURCE_DIR}/plugin/customClipPlugin.h
)
# Use C++11
target_compile_features(clipplugin PUBLIC cxx_std_11)
# Link TensorRT's nvinfer lib
target_link_libraries(clipplugin PRIVATE ${NVINFER_LIB})
# We need to explicitly state that we need all CUDA files
# to be built with -dc as the member functions will be called by
# other libraries and executables (in our case, Python inference scripts)
set_target_properties(clipplugin PROPERTIES
CUDA_SEPARABLE_COMPILATION ON
)
$ find / -name pybind* 2> /dev/null
$ find / -name cuda* 2> /dev/null
$ find / -name libnvinfer.so 2> /dev/null
$ find / -name NvInfer.h 2> /dev/null or find / -name NvUffParser.h 2> /dev/null
$ which cmake
//필요사항 cmake, pybind11 필요
$ sudo apt install cmake
$ sudo pip3 install pybind11
- C++ PlugIn Build 진행
$ echo $PATH /home/nvidia/.local/bin:/usr/local/cuda-10.0/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin // cmake 실행시 CUDACXX 를 /etc/environment 넣거나, CMAKE_CUDA_COMPILER=/usr/local/cuda-10.0/bin/nvcc 설정진행 $ sudo vi /etc/environment PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games" CUDACXX=/usr/local/cuda-10.0/bin/nvcc $ sudo mkdir build && pushd build $ sudo cmake .. or //X86기반 설정을 ARM으로 현재사항에 맞게변경 $ sudo cmake .. \ -DPYBIND11_DIR=/usr/local/include/python3.6/pybind11/ \ -DCUDA_ROOT=/usr/local/cuda-10.0/ \ -DPYTHON3_INC_DIR=/usr/include/python3.6/ \ -DNVINFER_LIB=/usr/lib/aarch64-linux-gnu/libnvinfer.so \ -DTRT_INC_DIR=/usr/include/aarch64-linux-gnu/ \ -DTRT_LIB=/usr/lib/aarch64-linux-gnu/ $ sudo make -j Scanning dependencies of target clipplugin [ 50%] Building CXX object CMakeFiles/clipplugin.dir/plugin/customClipPlugin.cpp.o [ 50%] Building CUDA object CMakeFiles/clipplugin.dir/plugin/clipKernel.cu.o [ 75%] Linking CUDA device code CMakeFiles/clipplugin.dir/cmake_device_link.o [100%] Linking CXX shared module libclipplugin.so [100%] Built target clipplugin $ popd
빌드관련 설정사항 (CUDACXX)
https://github.com/jetsonhacks/buildLibrealsense2TX/issues/13
- MNIST Training과 TEST 진행 후 모델로 저장
$ sudo python3 lenet5.py ...... Epoch 1/10 2019-09-06 15:23:04.843040: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcublas.so.10.0 60000/60000 [==============================] - 8s 139us/sample - loss: 0.2036 - acc: 0.9403 Epoch 2/10 60000/60000 [==============================] - 8s 126us/sample - loss: 0.0816 - acc: 0.9756 Epoch 3/10 60000/60000 [==============================] - 7s 124us/sample - loss: 0.0525 - acc: 0.9839 Epoch 4/10 60000/60000 [==============================] - 7s 124us/sample - loss: 0.0375 - acc: 0.9879 Epoch 5/10 60000/60000 [==============================] - 7s 122us/sample - loss: 0.0277 - acc: 0.9915 Epoch 6/10 60000/60000 [==============================] - 7s 122us/sample - loss: 0.0223 - acc: 0.9928 Epoch 7/10 60000/60000 [==============================] - 7s 122us/sample - loss: 0.0158 - acc: 0.9948 Epoch 8/10 60000/60000 [==============================] - 7s 123us/sample - loss: 0.0152 - acc: 0.9949 Epoch 9/10 60000/60000 [==============================] - 7s 122us/sample - loss: 0.0104 - acc: 0.9969 Epoch 10/10 60000/60000 [==============================] - 7s 123us/sample - loss: 0.0119 - acc: 0.9961 10000/10000 [==============================] - 1s 73us/sample - loss: 0.0810 - acc: 0.9800 Test loss: 0.08098314766188651 Test accuracy: 0.9800000190734863 W0906 15:24:20.296670 547944542224 ............................
- 생성된 모델을 이용하여 예측 테스트
생성된 모델을 읽어서 Custom Layer를 적용후 Test Case와 예측 Case를 비교
$ sudo python3 sample.py
......
UFF Version 0.6.3
=== Automatically deduced input nodes ===
[name: "InputLayer"
op: "Placeholder"
attr {
key: "dtype"
value {
type: DT_FLOAT
}
}
attr {
key: "shape"
value {
shape {
dim {
size: -1
}
dim {
size: 1
}
dim {
size: 28
}
dim {
size: 28
}
}
}
}
]
=========================================
Using output node OutputLayer/Softmax
Converting to UFF graph
Warning: No conversion function registered for layer: CustomClipPlugin yet.
Converting trt_relu6 as custom op: CustomClipPlugin
W0906 15:26:19.200886 548537745424 deprecation_wrapper.py:119] From /usr/lib/python3.6/dist-packages/uff/converters/tensorflow/converter.py:179: The name tf.AttrValue is deprecated. Please use tf.compat.v1.AttrValue instead.
DEBUG: convert reshape to flatten node
No. nodes: 13
UFF Output written to /usr/src/tensorrt/samples/python/uff_custom_plugin/models/trained_lenet5.uff
UFF Text Output written to /usr/src/tensorrt/samples/python/uff_custom_plugin/models/trained_lenet5.pbtxt
=== Testing ===
Loading Test Case: 6
Prediction: 6
$ ls models // models directory 생성되었으며, pb/uff 파일 생성
trained_lenet5.pb trained_lenet5.pbtxt trained_lenet5.uff
2. TensorRT Python Custom Layer(C++) 소스
왜 Tensorflow의 Layer 중 TensorRT로 사용시 제약사항있어 Custom Layer를 사용할까?
그리고, 언제 사용되는지에 대해 구체적으로 알고 싶었다.
우선 아래의 소스는 TensorRT가 ReLU6를 미지원해서 이를 Custom Layer를 재정의하여 사용하는 구조이다
- ReLU/ReLU6 의 차이
- Relu y = max(x ,0) 그래프, x좌표가 0기반으로 y좌표 증가
- Relu6 y = min(max(x, 0), 6) 그래프, x좌표가 0기반으로 y좌표 증가 x좌표의 6까지 한계
https://woolulu.tistory.com/84
https://www.tensorflow.org/api_docs/python/tf/nn/relu
https://www.tensorflow.org/api_docs/python/tf/nn/relu6
http://www.cs.utoronto.ca/~kriz/conv-cifar10-aug2010.pdf
- Tensorflow와 TensorRT 제약사항
우선 TensorRT의 제약사항을 아래에서 확인가능하다
그리고, 두번째 Site에서 Tensorflow의 UFF Parser 지원사항을 보면 ReLU6 지원가능을 볼수 있다
이렇게 보면 TensorRT도 지원가능할 것 같지만, 이것은 UFF Parser까지만 인식가능가능하다는 말이다
https://docs.nvidia.com/deeplearning/sdk/tensorrt-support-matrix/index.html
https://docs.nvidia.com/deeplearning/sdk/tensorrt-support-matrix/index.html#supported-ops
UFF에서 인식가능
https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/python_api/uff/Operators.html?highlight=relu#activation
- TensorRT API C++/Python 확인 (Activition Layer에서 ReLu만 지원)
Python의 API를 보면 더 쉽다
https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#layers
https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/c_api/classnvinfer1_1_1_i_activation_layer.html
https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/c_api/namespacenvinfer1.html#acbd177748000d30ae0277ee980757eb6
https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/python_api/infer/Graph/Layers.html#iactivationlayer
- TensorRT로 Network 직접 구성할때 Relu 예제참조 (C++/Python)
https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#create_network_c
https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#create_network_python
- DLA의 ReLu 제약사항 (참고사항, Xavier만 해당)
2.1 lenet5.py 분석
이전 소스와 거의 유사하지만 아래의 build_model시 network 구조가 다르다고 보면된다
$ cat lenet5.py
import tensorflow as tf
import numpy as np
import os
WORKING_DIR = os.environ.get("TRT_WORKING_DIR") or os.path.dirname(os.path.realpath(__file__))
## 생성될 Model의 저장장소
MODEL_DIR = os.path.join(
WORKING_DIR,
'models'
)
## Google mnist data를 download하여 ReShape 진행
def load_data():
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
## 기존과 다르게 reshape를 하여, 1차원을 추가하는데, -1 값이 60000 과 10000로 정의되는 것 같음
## https://docs.scipy.org/doc/numpy/reference/generated/numpy.reshape.html#numpy.reshape
x_train = np.reshape(x_train, (-1, 1, 28, 28))
x_test = np.reshape(x_test, (-1, 1, 28, 28))
return x_train, y_train, x_test, y_test
## Tensorflow Keras를 이용하여 Model의 Network 정의
def build_model():
# Create the keras model
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.InputLayer(input_shape=[1, 28, 28], name="InputLayer"))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(512))
## ReLU6 부분이 TensorRT로 Custom Layer로 재정의 될 부분이다
## TensorRT는 ReLU6을 지원하지 못하므로, 이 부분을 C++로 PlugIn으로 재정의하고 Custom Layer로 구현한다
## https://devtalk.nvidia.com/default/topic/1037149/tensorrt/relu6-not-supported-in-tensorrt-for-mobilenetv2/
model.add(tf.keras.layers.Activation(activation=tf.nn.relu6, name="ReLU6"))
model.add(tf.keras.layers.Dense(10, activation=tf.nn.softmax, name="OutputLayer"))
return model
## Model의 Build 부터 설정 부터 Training
def train_model():
## 기본 Network 정의
# Build and compile model
model = build_model()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
## Model의 TESTSET의 Download와 설정변경
# Load data
x_train, y_train, x_test, y_test = load_data()
## 실제 Training 할 숫자 정의, epochs , verbose는 1은 Prograss bar 설정
# Train the model on the data
model.fit(
x_train, y_train,
epochs = 10,
verbose = 1
)
## 실제 Training 과 TEST 진행
# Evaluate the model on test data
test_loss, test_acc = model.evaluate(x_test, y_test)
print("Test loss: {}\nTest accuracy: {}".format(test_loss, test_acc))
return model
## Save Model를 위해서 Mkdir
def maybe_mkdir(dir_path):
if not os.path.exists(dir_path):
os.makedirs(dir_path)
## Training/Test가 된 model을 freezing 하여 저장
def save_model(model):
output_names = model.output.op.name
sess = tf.keras.backend.get_session()
graphdef = sess.graph.as_graph_def()
frozen_graph = tf.graph_util.convert_variables_to_constants(sess, graphdef, [output_names])
frozen_graph = tf.graph_util.remove_training_nodes(frozen_graph)
# Make directory to save model in if it doesn't exist already
maybe_mkdir(MODEL_DIR)
model_path = os.path.join(MODEL_DIR, "trained_lenet5.pb")
with open(model_path, "wb") as ofile:
ofile.write(frozen_graph.SerializeToString())
if __name__ == "__main__":
## Model 생성부터 Training/Test 관련 설정 과 Training/Test 진행
model = train_model()
## 생성된 Model 저장
save_model(model)
- Tensorflow Keras model 관련함수
https://www.tensorflow.org/api_docs/python/tf/keras/Sequential
2.2 sample.py 분석
$ cat sample.py
import sys
import os
import ctypes
from random import randint
from PIL import Image
import numpy as np
import tensorflow as tf
import pycuda.driver as cuda
import pycuda.autoinit
import tensorrt as trt
import graphsurgeon as gs
import uff
# ../common.py
sys.path.insert(1,
os.path.join(
os.path.dirname(os.path.realpath(__file__)),
os.pardir
)
)
import common
# lenet5.py
import lenet5
# MNIST dataset metadata
MNIST_IMAGE_SIZE = 28
MNIST_CHANNELS = 1
MNIST_CLASSES = 10
WORKING_DIR = os.environ.get("TRT_WORKING_DIR") or os.path.dirname(os.path.realpath(__file__))
# Path where clip plugin library will be built (check README.md)
CLIP_PLUGIN_LIBRARY = os.path.join(
WORKING_DIR,
'build/libclipplugin.so'
)
# Path to which trained model will be saved (check README.md)
MODEL_PATH = os.path.join(
WORKING_DIR,
'models/trained_lenet5.pb'
)
# Define global logger object (it should be a singleton,
# available for TensorRT from anywhere in code).
# You can set the logger severity higher to suppress messages
# (or lower to display more messages)
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
## 기본설정된 정의는 이곳에서 모두 확인
# Define some global constants about the model.
class ModelData(object):
INPUT_NAME = "InputLayer"
INPUT_SHAPE = (MNIST_CHANNELS, MNIST_IMAGE_SIZE, MNIST_IMAGE_SIZE)
RELU6_NAME = "ReLU6"
OUTPUT_NAME = "OutputLayer/Softmax"
OUTPUT_SHAPE = (MNIST_IMAGE_SIZE, )
DATA_TYPE = trt.float32
## TensorRT의 Custom Layer 연결부분 (핵심)
# Generates mappings from unsupported TensorFlow operations to TensorRT plugins
def prepare_namespace_plugin_map():
# In this sample, the only operation that is not supported by TensorRT
# is tf.nn.relu6, so we create a new node which will tell UffParser which
# plugin to run and with which arguments in place of tf.nn.relu6.
## Model의 ReLU6 -> trt_relu6 Layer 재정의하고 , 이 부분을 C++에서 Custom Layer에 연결구현
## customClipPlugin.cpp의 CustomClipPlugin 연결하며, clipMin ,clipMax Argument로 설정 Plugin의 Arg
## IPluginV2 C++ Class 의 Override로 구현(customClipPlugin.cpp)하고 있으며, 아래의 TensorRT C++ 참조
## https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/c_api/classnvinfer1_1_1_i_plugin_v2.html
## python API- create_plugin_node
## https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/python_api/graphsurgeon/graphsurgeon.html
## https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#graphsurgeon
## 상위 C++ 소스는 iPlugInv2를 사용하며, 이로 재정의한다
## iPlugIn도 Python API가 있는데, C++ 예제만 있으니, 이소스의 한계는 여기까지이다.
## clipMax/clipMin 값은 상위 Relu/Relu6의 차이를 보면될 것 같다
# The "clipMin" and "clipMax" fields of this TensorFlow node will be parsed by createPlugin,
# and used to create a CustomClipPlugin with the appropriate parameters.
trt_relu6 = gs.create_plugin_node(name="trt_relu6", op="CustomClipPlugin", clipMin=0.0, clipMax=6.0)
namespace_plugin_map = {
ModelData.RELU6_NAME: trt_relu6
}
return namespace_plugin_map
## PB파일이름을 UFF파일으로 변경
# Transforms model path to uff path (e.g. /a/b/c/d.pb -> /a/b/c/d.uff)
def model_path_to_uff_path(model_path):
uff_path = os.path.splitext(model_path)[0] + ".uff"
return uff_path
## PB파일을 UFF로 변경하는 것으로 PB파일과 PlugIN 정보
# Converts the TensorFlow frozen graphdef to UFF format using the UFF converter
def model_to_uff(model_path):
## Model의 Layer 중 ReLU6 이 부분을 C++ PlugIn으로 연결하고 재정의
# Transform graph using graphsurgeon to map unsupported TensorFlow
# operations to appropriate TensorRT custom layer plugins
dynamic_graph = gs.DynamicGraph(model_path)
dynamic_graph.collapse_namespaces(prepare_namespace_plugin_map())
## UFF File로 저장
# Save resulting graph to UFF file
output_uff_path = model_path_to_uff_path(model_path)
uff.from_tensorflow(
dynamic_graph.as_graph_def(),
[ModelData.OUTPUT_NAME],
output_filename=output_uff_path,
text=True
)
return output_uff_path
## Build TensorRT Engine이며, Pb파일을 UFF로 변경하고 이를 기준으로 정의
# Builds TensorRT Engine
def build_engine(model_path):
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.UffParser() as parser:
builder.max_workspace_size = common.GiB(1)
## PB를 UFF로 변경 상위 함수 호출
uff_path = model_to_uff(model_path)
## INPUT_SHAPE 1,28,28로 설정
parser.register_input(ModelData.INPUT_NAME, ModelData.INPUT_SHAPE)
parser.register_output(ModelData.OUTPUT_NAME)
parser.parse(uff_path, network)
## TensorRT Engine 생성
return builder.build_cuda_engine(network)
## pagelocked_buffer는 Host(CPU) input buffer에 Data 저장 하고 random으로 test case를 설정하고 이 결과를 반환
# Loads a test case into the provided pagelocked_buffer. Returns loaded test case label.
def load_normalized_test_case(pagelocked_buffer):
_, _, x_test, y_test = lenet5.load_data()
num_test = len(x_test)
case_num = randint(0, num_test-1)
img = x_test[case_num].ravel()
np.copyto(pagelocked_buffer, img)
return y_test[case_num]
def main():
## PlugIn File 없으면, 에러처리
# Load the shared object file containing the Clip plugin implementation.
# By doing this, you will also register the Clip plugin with the TensorRT
# PluginRegistry through use of the macro REGISTER_TENSORRT_PLUGIN present
# in the plugin implementation. Refer to plugin/clipPlugin.cpp for more details.
if not os.path.isfile(CLIP_PLUGIN_LIBRARY):
raise IOError("\n{}\n{}\n{}\n".format(
"Failed to load library ({}).".format(CLIP_PLUGIN_LIBRARY),
"Please build the Clip sample plugin.",
"For more information, see the included README.md"
))
## PlugIn을 동적 라이브러리 연결
ctypes.CDLL(CLIP_PLUGIN_LIBRARY)
## 학습된 Model이 없으면 에러 발생
# Load pretrained model
if not os.path.isfile(MODEL_PATH):
raise IOError("\n{}\n{}\n{}\n".format(
"Failed to load model file ({}).".format(MODEL_PATH),
"Please use 'python lenet5.py' to train and save the model.",
"For more information, see the included README.md"
))
## build_engine 함수 호출
# Build an engine and retrieve the image mean from the model.
with build_engine(MODEL_PATH) as engine:
## 기존의 common.py 참조하면, host(CPU) /device(GPU) buffer 할당
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
## Engine 생성
with engine.create_execution_context() as context:
## 기존과 동일하게 host(CPU) 정보를 넣고, Random으로 설정한 test_case 표시
print("\n=== Testing ===")
test_case = load_normalized_test_case(inputs[0].host)
print("Loading Test Case: " + str(test_case))
## common.py의 inference해서 얻은 결과 표시하여 상위 값과 비교
# The common do_inference function will return a list of outputs - we only have one in this case.
[pred] = common.do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
print("Prediction: " + str(np.argmax(pred)))
if __name__ == "__main__":
main()
3. TensorRT Python Custom Layer(Python) 소스
상위 구현된 IPluginV2와 관련된 함수를 Python으로 구현을 한번 해보자
아래와 같이 Python으로도 IPlugInV2를 지원을 해주고 있다
Python의 iPlugInv2 부분 아래 주소
https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/python_api/infer/Plugin/pyPlugin.html
https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/python_api/infer/Plugin/IPluginV2.html
다음은 Custom Layer의 예제 C++과 Python의 예제를 다루고 있다
Custom Layer C++ Example
https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#add_custom_layer
3.1 Python Custom Layer Example
Python Custom Layer Example은 이곳을 보면 되고 구성은 두개로 나뉘어 지면, 연결하는 Interface인 IPlugin에 관련되어서만 서술하고 있다.
Custom Layer의 구현에 대해서 별다른 이야기가 없다
TensorRT Manual이 계속 변경되니, 추후에 예제도 추가될지도 모른다
https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#add_custom_layer_python
- Layer를 새롭게 정의하여 Network에 추가방식 (IPluginCreator)
Layer의 구체적인 동작방식은 정의하지 않았다 (동작방식은 C++로 구현?)
https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#example1_add_custom_layer_python
https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/python_api/infer/Plugin/IPluginCreator.html
https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/python_api/infer/Graph/Network.html?highlight=add_plugin_v2#tensorrt.INetworkDefinition.add_plugin_v2
- UFF Parser에 존재하는 Layer를 재정의해서 구현하는 방식 (IPluginV2)
https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#example2_add_custom_layer_no_uff_python
만약 상위 소스를 Python으로만 수정한다면 PlugIn의 Custom Layer부분이 Serialize가 되어야 할 것인데, 이 부분이 어떻게 될까 한번 생각해보면, 일단
C++은 Compiler라서 이미 Binary이기때문에 Serialize가 쉽지만, Python은 Interpreter 이므로 PlugIn을 Python으로 구현하면 성능뿐만 아니라, 동작구현에도 어려움이 있을 것 같다
내 개인생각으로는 PlugIn은 Python으로 해도, 동작방식(Custom Layer)은 C++으로 구현을 해야할 것 같다
이 부분은 생각해볼만한 문제이며, 만약 순수 Python 구현된 Custom Layer 예제가 나오면 어떻게 나올지 궁금하다